Introduction
Continuing evolution of SARS-CoV-2 in humans leads to emergence of new variants with novel epidemiological and/or antigenic properties. In spring 2020, the S:D614G change has spread globally due to its fitness advantage [1,2]. Subsequently, a number of variants of concern, including B.1.1.7 (501Y.V1) first sampled in Great Britain in September, B.1.351 (501Y.V2) first sampled in South Africa in October, and P.1 (501Y.V3) first sampled in Brazil in December, were shown to be associated with increased transmissibility [3–5]. These variants are characterized by overlapping sets of changes in spike receptor-binding domain which affects ACE2 binding and antibody recognition, as well as other changes with demonstrated functional and antigenic effects. Emergence of SARS-CoV-2 variants with evidence for change in transmissibility, and possibly other properties, highlights the importance of continued surveillance of novel variants. In particular, locally arising variants that grow in frequency over time may suggest a transmission advantage, although such an increase may also occur by chance [6].
Here, we show that the outbreak in Russia is characterized by a spread of two lineages, B.1.1.317 and B.1.1.397+, which are highly prevalent in Russia but rarely appear in non-Russian samples. We trace the accumulation of sequential mutations in the evolution of these lineages, and single out the spike mutations that are followed by a burst in frequency. If the frequency increase of B.1.1.317 and B.1.1.397+ has been indeed driven by changes in the intrinsic properties of the virus rather than by epidemiology, it is these mutations in spike that most likely have led to this increase, although importantly we lack direct transmission data to verify this causality. We also describe three novel candidate variants of interest that are characterized by a rapid increase in frequency and combinations of important spike mutations, including the E484K mutation of concern.
Results
High-frequency variants in Russia
We analyzed 4,487 SARS-CoV-2 sequences with known sampling dates obtained in Russia between February 25, 2020 - March 28, 2021. 2,842 of these samples are deposited to GISAID [7], while the remaining 1,645 (all dating to February-November 2020) will be made available through another repository. All 968 analyzed samples from December 2020 - March 2021 are available on GISAID. The vast majority of samples over this period came from several genomic surveillance programs which were not targeted towards particular variants, although representation of Russia’s regions varied with time.
Throughout the pandemic, the SARS-CoV-2 diversity in Russia has been predominated by the B.1.1 Pango lineage which is frequent in Europe, as well as lineages descendant from it [8] (Fig. 1).

Fig. 1. Dynamics of Pango lineage frequencies in Russia (top row) and among the non-Russian samples in GISAID (bottom row). The data presented is for all sequences collected between December 2019 - April 2021. Asterisks in Pango lineage designations correspond to pooled sets of lineages of that hierarchy level, except those listed in other categories; e.g., B.1.1.* includes B.1.1 and B.1.1.6 but not B.1.1.7 or B.1.1.317. Samples are split into 1 month bins.
To find the non-reference amino acid variants that gained in frequency in Russia, we selected the positions at which the mean frequency of the non-reference variant in Russian samples exceeded 5% (for the spike) or 10% (for other proteins) in February-March 2021. We found 21 such positions in spike and 21 such positions in other proteins. Among these changes, two (RdRp:P323L and S:D614G) were fixed early in the global evolution of SARS-CoV-2; other two (N:R203K and N:G204R) are the lineage-defining mutations of B.1.1.
The frequency dynamics of the derived variants at the remaining 38 positions is shown in Fig. 2. These include the mutations characterizing the B.1.1.7 variant which has been increasing in frequency in Russia since January 2021 (Fig. 1), as well as some of the other globally spreading mutations of concern or interest, including the E484K mutation in spike. However, at many of these sites, the non-reference variants were rare outside Russia (Fig. 2). Most of these variants showed similar temporal dynamics in Moscow and St. Petersburg regions, as well as in the European and Asian parts of Russia (Fig. S1), indicating that their increase in frequency is not a result of sampling bias.
We aimed to identify the high-frequency variants carrying these mutations. Many of these sites were highly homoplasic, and overall we found the resulting phylogenies not to be robust. Instead, we defined the most frequent variants composed of these mutations, independent of the alleles at other sites (Fig. 3).
We considered the allele combinations that were most frequent in Russia in February-March 2021, and noticed that they belonged to several nested sets. The most frequent combination (99 out of the 461 samples) carried the N:A211V mutation which is characteristic of the B.1.1.317 Pango lineage; the second most frequent combination carried the S:D138Y and ORF8:V62L combination of mutations which are characteristic of the B.1.1.397 lineage; the third combination carried the set of characteristic mutations of B.1.1.7.
Still, there was no one-to-one correspondence between the frequent combinations of mutations and Pango lineages. For example, while the most frequent variant carrying S:M153T was that also including N:M234I, S:D138Y and ORF8:V62L (column 2 in Fig. 3), and classified as Pango lineage B.1.1.397, the variants carrying S:M153T alone, the S:M153T+N:M234I combination and the S:M153T+N:M234I+S:N679K combination were also frequent (columns 4, 9 and 5 in Fig. 3 respectively) but were classified by PANGOLIN as other lineages (B.1.1, B.1.1.141, B.1.1.28 and others). Similarly, while B.1.1.317 is defined by the N:A211V mutation, the frequency of the variant carrying this mutation alone is currently relatively low (column 12 in Fig. 3), while most samples carrying it also carry 8 additional high-frequency mutations, including four potentially important changes in spike (Q675R+D138Y+S477N+A845S; column 1 in Fig. 3). The frequencies of such “non-canonical” combinations of mutations increased throughout 2020-2021 (Fig. 4).
Finally, some of the observed high-frequency combinations of mutations, including the S:E484K mutation of concern as well as other mutations of interest (notably S:Δ140-142, S:Δ136-144 and nsp6:Δ106-108, also referred to as ORF1a:Δ3675-3677; columns 7, 8 and 10 in Fig. 3), currently lack pangolin designations.

Fig. 2. Frequency dynamics of SARS-CoV-2 amino acid changes. Plots represent changes in frequency over time for the non-reference amino acid mutations that reached frequencies above 10% (5% for the S protein) among the 461 Russian samples obtained in February-March 2021. The frequency of B.1.1.7 is represented by the mutation nsp3:I1412T; deletions nsp6:Δ106-108 and S:Δ144 and substitution S:P681H which are a part of B.1.1.7 as well as other lineages are shown separately; the remaining 14 mutations such that >70% of samples carrying them belonged to B.1.1.7 are not shown. Changes in frequency in Russian (red) and non-Russian (blue) samples are shown in one-month time intervals. Shaded areas show confidence intervals (Wilson score intervals).

Fig. 3. Variants with high frequencies in Russia in February-March. Horizontal rows represent all positions with non-reference alleles at frequency above 5% (for spike protein) or 10% (for other proteins) in Russia in February-March. Columns represent observed combinations of these variants including 2 or more samples, with black dots indicating the presence of the non-reference variant.

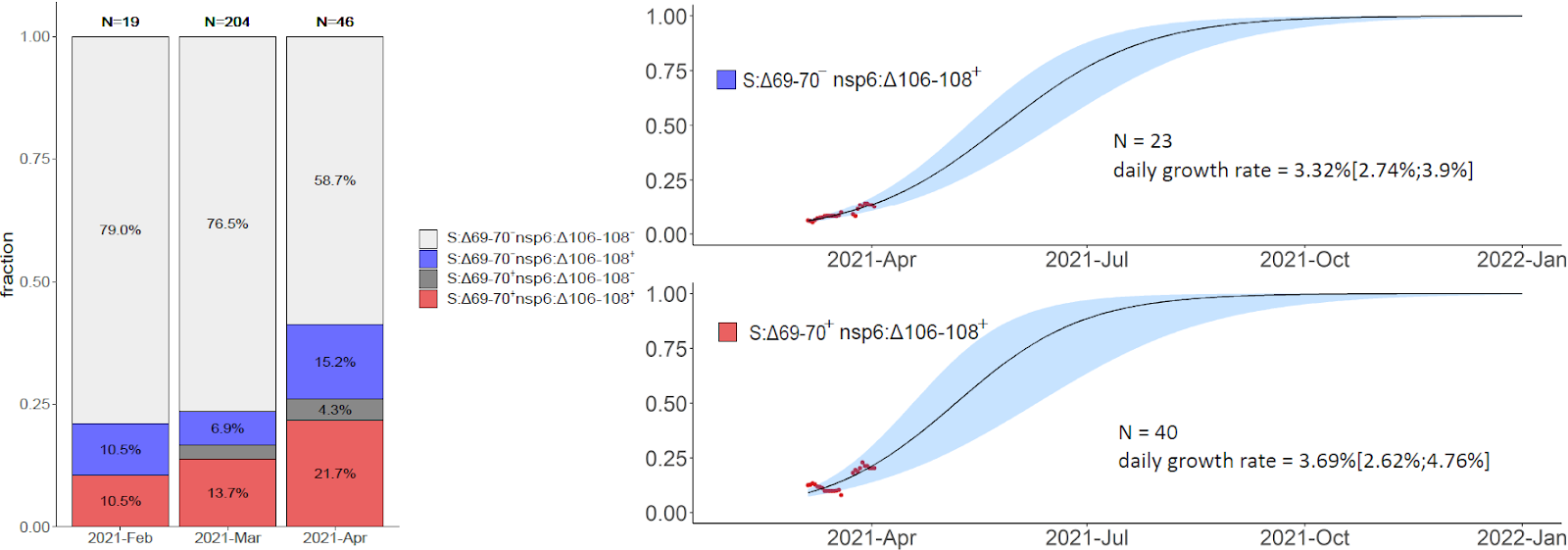
Fig. 4. Mutational composition and frequency dynamics of the B.1.1.317 and B.1.1.397+ lineages. A, B: schematic representation of the B.1.1.317 and B.1.1.397+ lineages. Pango lineage designations are approximate. C: Muller plots representing the frequency dynamics of the corresponding combinations of mutations in Russia.
Frequency dynamics of the variants prevalent in Russia
To study potential effects of individual mutations composing a variant on the frequency dynamics of this variant, we fit the logistic growth model for the 10 most-frequent combinations of mutations and for N:A211V (which is the 12th most-frequent combination), and compared the dynamics of nested combinations with each other (Figs. 5-7).
The variant carrying just the N:A211V change (largely coincident with the B.1.1.317 Pango lineage) has increased in frequency since the start of the epidemic in Russia. However, since fall 2020, it is being displaced by the variant with 8 additional mutations, including four in spike: Q675R+D138Y+S477N+A845S. When the logistic growth model is fit to the N:A211V variant alone, it demonstrates modest growth (Fig. 5, top); however, its combination with S:Q675R+D138Y+S477N+A845S demonstrates a much more rapid frequency increase, with the estimated daily growth rate of 1.93% (95% CI: 1.8%‒2.06%; Fig. 5, center). While this leads to a frequency increase of the N:A211V mutation independent of the background (Fig. 5, bottom), this suggests that the frequency increase is more likely driven by the S:Q675R+D138Y+S477N+A845S combination than the N:A211V change defining the B.1.1.317 Pango lineage.
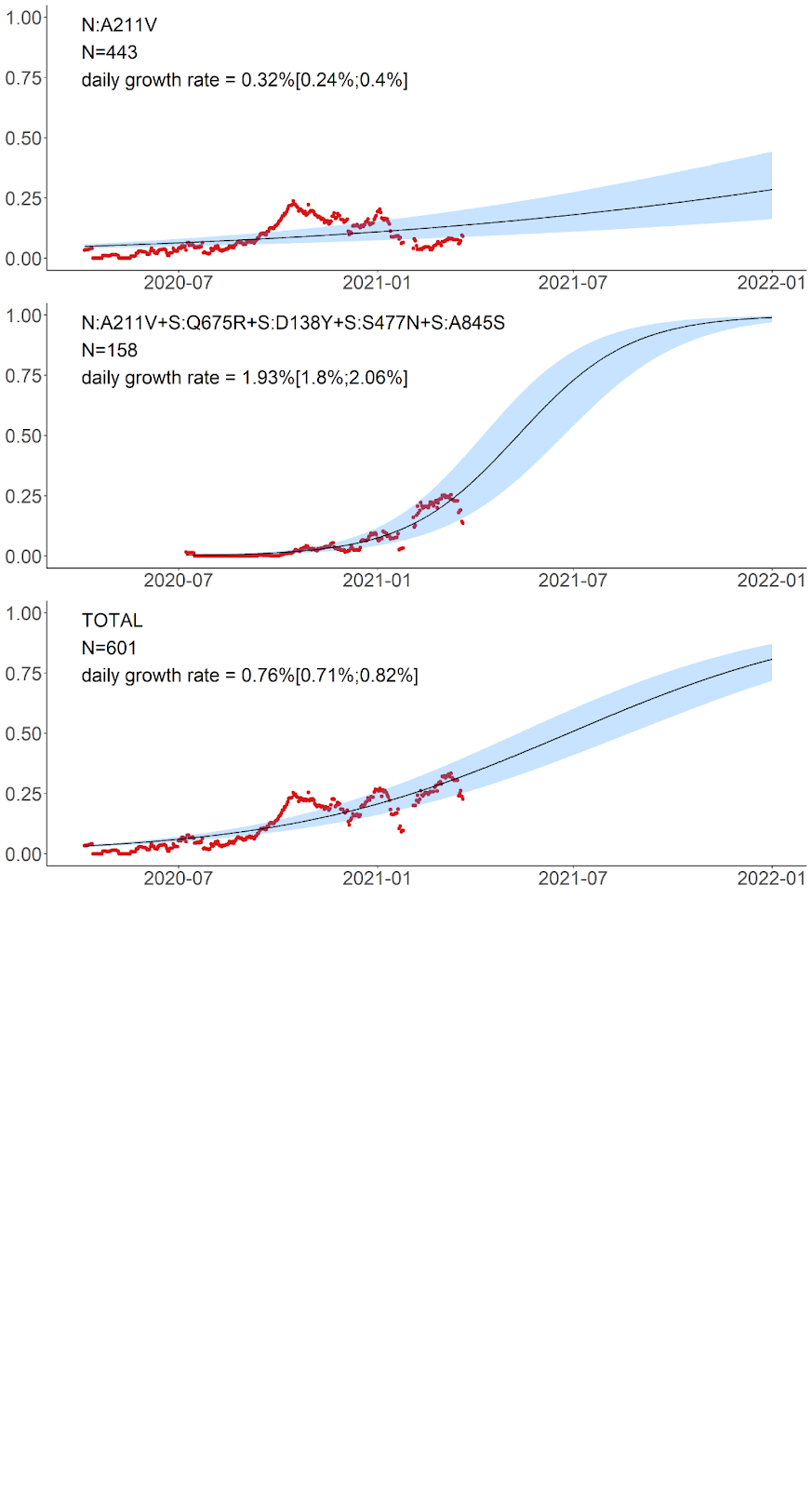
Fig. 5. Logistic growth model for nested variants defined by amino acid changes in the N:A211V context. Red dots, sliding window 14-day average frequency; shaded area, 95% confidence interval. Variants are identified according to the presence of the mutations in S and N proteins; see Fig. 4 for complete lists of mutations in the corresponding variants.
By contrast, the frequency of the S:M153T mutation grows independently of the presence of other mutations from our list (Fig. 6). While subsequent mutations may add to the estimated growth rates, these rates are comparable when the S:M153T mutation occurs alone or in combination with N:M234I, N:M234I+S:N679K, or N:M234I+S:D138Y, and all these combinations are still frequent many months after they all originated (Fig. 4, 6).
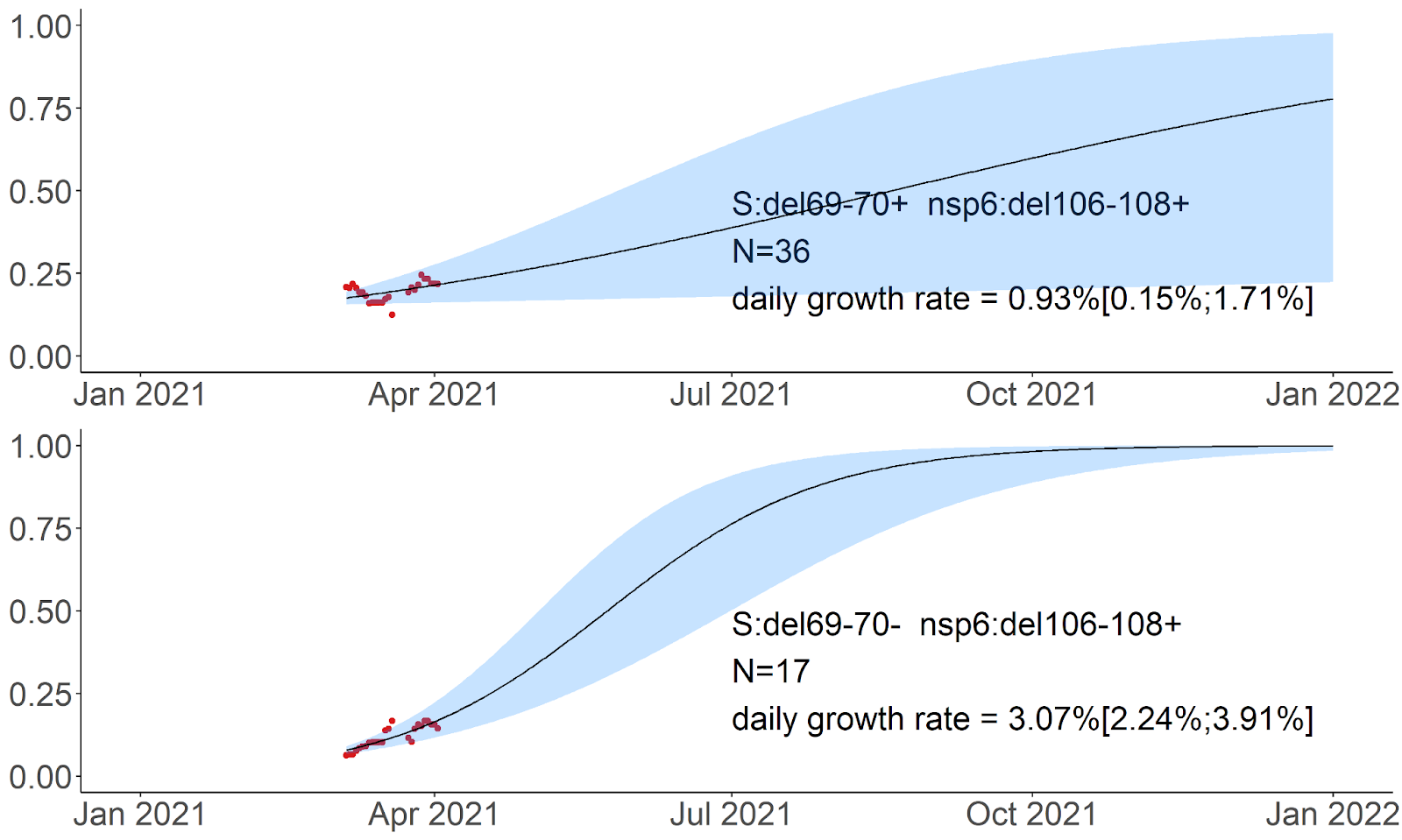
Finally, the five remaining variants which also reached high frequency in February-March carry unnested, although partially overlapping sets of mutations. These include the B.1.1.7 variant; a variant carrying the S:P681H mutation of interest in the absence of other high-frequency mutations; as well as three novel variants carrying the following combinations of mutations: (i) nsp6:Δ106-108+S:P9L+S:Δ140-142 (nine of these 14 samples are currently classified by PANGOLIN as B.1.1.74, four as B.1.1, and one as B.1.1.354); (ii) S:P9L+S:Δ136-144+S:E484K (which recently got the AT.1 PANGOLIN designation); and (iii) nsp6:Δ106-108+S:Δ144+S:E484K (currently classified by PANGOLIN as B.1.1). The latter three variants were only observed in 13-14 samples each, but are of interest because this constitutes an appreciable fraction of samples obtained in February-March, and also because they are composed of known mutations of interest or concern. The daily growth rate estimated for these variants by the logistic growth model is in the range of 2.44% to 7.18% (Fig. 7).

Fig. 6. Logistic growth model for variants defined by amino acid changes in the S:M153T context. Notations are the same as in Fig. 5.
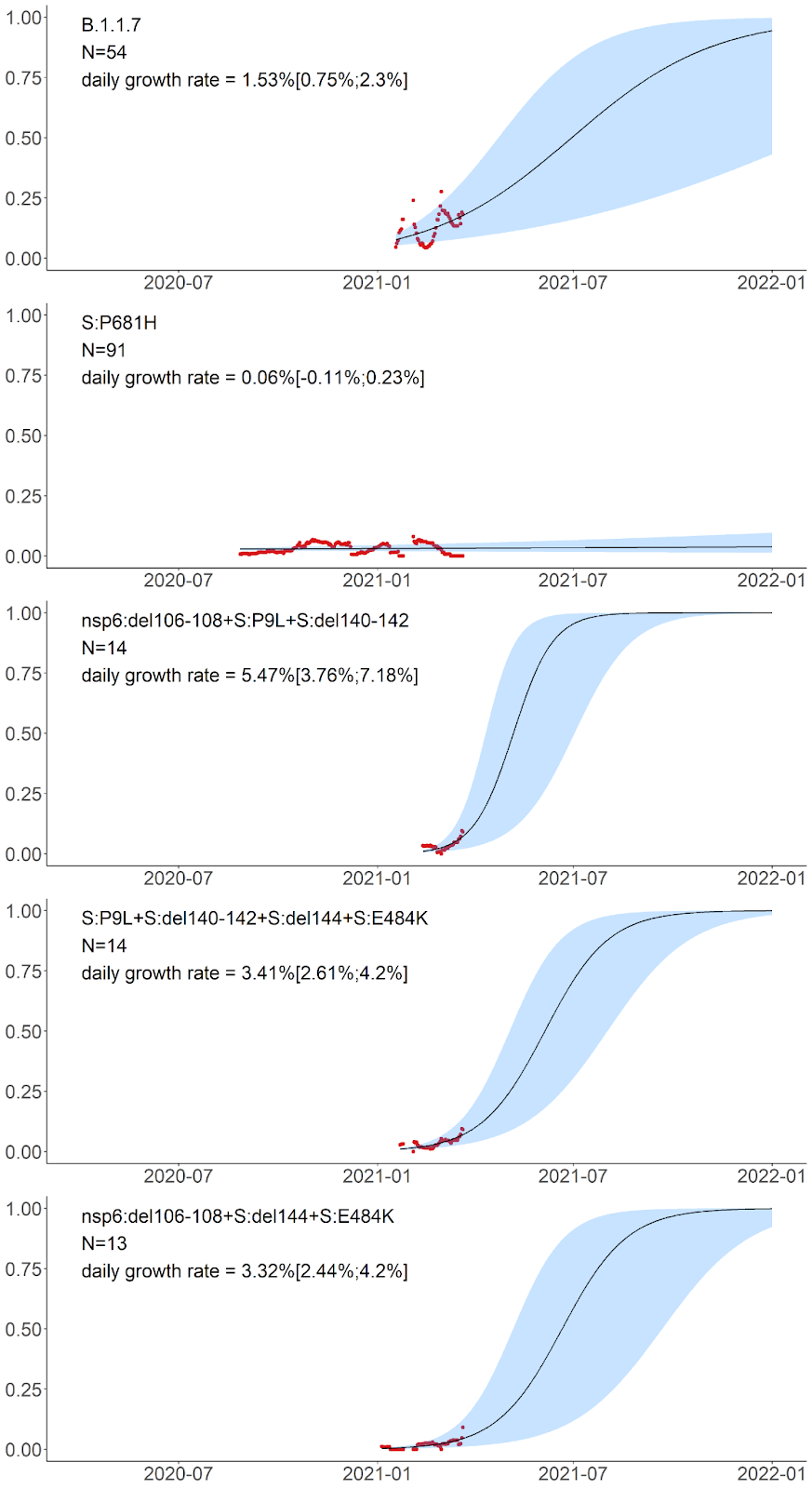
Fig. 7. Logistic growth model for the five remaining amino acid variants with high frequencies in Russia in February-March. Notations are the same as in Fig. 5. S:P681H has been observed both independently and as part of B.1.1.7; in panel B, the cases of B.1.1.7 are not shown, by excluding the S:P681H+S:N501Y combination.
Mutational composition of the high-frequency variants
In this section, we discuss the mutations that constitute the variants spreading in Russia.
B.1.1.317. This lineage, first sampled in Vietnam on March 27, 2020 [9], is defined by the presence of the N:A211V mutation. Changes at nucleocapsid position 211 experience both persistent (according to the FEL model of HyPhy [10]) and episodic (according to the MEME model [11]) positive selection12 as well as a rapid increase in frequency of non-reference variants [12]. While the global frequency of 211V has remained low (<0.4%), in Russia, it has reached 26.9% in February-March 2021. According to immunoinformatic analysis, site N:211 is included in one of the four regions of the nucleocapsid protein with the highest affinity to multiple MHC-I alleles [13]. Nevertheless, the frequency of the variant carrying the N:A211V mutation alone has declined since October 2020 (Fig. 4), suggesting that it is unlikely to confer transmission advantage against the background of other currently frequent variants (Fig. 5).
A rapidly spreading subclade within B.1.1.317 carries the (Q675R+D138Y+S477N+A845S) combination of changes in spike. Two of these mutations are of interest. S:D138Y, first described as one of the lineage-defining mutations of the P.1 lineage [14], is a change in the N-terminal domain (NTD) of spike. Site 138 is adjacent to the NTD antigenic supersite, and together with other NTD mutations of P.1, S:D138Y was suggested to be the cause of disruption of binding with mAb159 [15] which is one of the most potent inhibitory antibodies [16]. S:S477N is positioned in the receptor-binding motif (RBM) of the S-protein near the antibody binding site (Fig. 8) and was reported to promote resistance to multiple antibodies and plasma from convalescent patients [17,18]. Additionally, S477N is thought to increase ACE2 binding [19]. It is one of the lineage-defining mutations of the B.1.160 (20A.EU2) variant of interest prevalent in Europe in Autumn 2020 [20], and the only one among them to occur in the S-protein; it also defines one of the two subclades of the B.1.526 variant of interest currently spreading in the USA. S:Q675R is located at the central part of S1 (Fig. 8), and S:A845S, in S2; the significance of these two mutations is unknown.
B.1.1.397+. S:M153T is the characteristic mutation of B.1.1.397, which also comprises several other mutations. However, the frequency of S:M153T in Russia also increases in the absence of these other mutations (Fig. 6). This increase has been ongoing since late spring 2020 (Fig. 4), and has been noticed in Russia [21,22]. S:M153T, however, has remained rare outside Russia. S:153 is the first position of the 6-amino acid insertion specific to SARS-CoV-2 and some closely related bat betacoronaviruses that was absent in SARS-CoV [23]. While the effect of S:M153T on antigenic properties is unknown, S:153 is a part of the N3 loop of the NTD. This loop is a part of the NTD antigenic supersite (Fig.8; [24]), and nearby residues, including S:152, were recently shown to bind highly neutralizing 4A8 antibody from a convalescent patient [25]. Besides Russia, S:M153T is prevalent in Kazakhstan [26] which has a long border with Russia, suggesting common ancestry of this change in these countries.
The most frequent subclade within B.1.1.397, and the one with some evidence for an independent increase in frequency (Fig. 6), is defined by the presence of two additional mutations of interest: S:D138Y discussed above in the context of the B.1.1.317 lineage (but acquired in the B.1.1.397 lineage independently); and N:M234I. Position N:234 is a part of a disordered linker domain of the nucleocapsid protein [27]. Outside B.1.1.397, the N:M234I change has also occurred independently in several lineages that attracted attention. It is among the lineage-defining mutations of the B.1.160 (20A.EU2) lineage as well as the B.1.526 lineage that increases in frequency in the USA at rates comparable to those of B.1.1.7 [28]. It is also one of the changes defining a newly detected lineage (preliminarily identified as B.1.x) which also contains S:N501Y and S:P681H and seems to spread rapidly in the USA [29]. Independent emergence of N:M234I in several variants of interest may reflect its impact on at least one of multiple functions of the N protein [30].
Other notable variants. The five other combinations of mutations observed at high frequencies in Russia in February-March 2021 are B.1.1.7, the best-known variant with increased transmissibility; the variant carrying the S:P681H mutation alone; and three novel variants.
S:P681H is one of the nine spike changes that characterize the rapidly spreading B.1.1.7 lineage [3]; however, it is absent from the two other lineages of concern, B.1.351 and P.1, indicating that it is not essential for increased transmissibility. The 681 position is adjacent to the furin cleavage site; this site is absent in non-human CoV, and is assumed to have contributed to pathogenicity in humans [31]. Changes at this position experience both persistent and episodic positive selection [12]. P681H appears to increase in frequency globally [32], although it is hard to disentangle this increase from that of the other changes constituting the rapidly spreading B.1.1.7 lineage. We find that the frequency of this mutation in Russia in the absence of other B.1.1.7 mutations does not increase (Fig. 7), indicating that it does not increase transmissibility by itself.
The three remaining high-frequency variants with evidence for rapid frequency increase carry combinations of the following high-frequency mutations: S:P9L, S:Δ140-142 (or S:Δ136-144), S:E484K, and nsp6:Δ106-108. The sets of mutations in these variants are in conflict (i.e., not nested within each other; Fig. 3), indicating that at least some of these mutations emerged in them independently. These mutations are of interest or concern. Specifically, S:E484K is involved in multiple variants of concern including the B.1.351 (501Y.V2) [4], P.1 (501Y.V3) [5,33] and P.2 (S.484K) [5,33] lineages, and has been shown by several groups to cause escape from neutralizing antibodies [34–36]. nsp6:Δ106-108 (also referred to as ORF1a:Δ3675-3677) is a part of all three variants of concern. S:Δ140-142, S:Δ144 and S:Δ136-144 are distinct deletions at a recurrent deletion region of the spike glycoprotein which confer resistance to neutralizing antibodies [37].

Fig. 8. Position of residues 138, 153, 477 and 675 in the spatial structure of the S protein bound with 4A8 and 4-59 antibodies (PDB IDs: 7c2l and 7czx). Each of these residues is colored in its own color. Yellow, receptor binding domain; green, receptor binding motif; ocean blue, heavy chain of the 4A8 antibody; blue, heavy chain of the 4-59 antibody; olive, antibody binding epitope.
Discussion
Russia has been relatively well isolated in the course of COVID-19 pandemic: both the first cases of COVID-19 and the arrival of variants of concern, notably the B.1.1.7, have happened here later than in many European countries [8,38]. Together with the large size of the outbreak in Russia, such isolation could have created conditions for emergence of novel important domestic variants.
A steady increase in frequency of lineages B.1.1.317 and B.1.1.397+, as well as the presence of multiple mutations with potential effect on antigenic properties, notably S:D138Y, merit classification of these two lineages as variants of interest [39,40]. Nevertheless, the rate of spread of B.1.1.317 and B.1.1.397+ has been lower than that of VOCs (e.g., ~7% for B.1.1.7 [41]). In particular, while B.1.1.317 has been observed in Russia since April 2020, the subclade of B.1.1.317 carrying the three spike mutations, since July 2020, and B.1.1.397+, since April 2020, all these lineages have remained at frequencies below 30% in Russia, and the logistic growth rates estimated by our model are all below 2% (Fig. 5-6). Besides, these variants are currently missing spike changes L452R, E484K or N501Y which occur in other VOCs [40].
The combinations of mutations seen in the three variants that emerged in 2021 (Fig. 7) look more suspicious, because their estimated rate of frequency increase is higher and because they include mutations with known effects and occurring in other variants of interest or concern. While little can be told about their frequency dynamics on the basis of the currently available data, they require careful monitoring.
Methods
Dataset preparation. 1,060,545 sequences of SARS-CoV-2 were downloaded from GISAID on April 15, 2021 and aligned with MAFFT [42] v7.45324 against the reference genome Wuhan-Hu-1/2019 (NCBI ID: MN908947.3) with --addfragments --keeplength options. 100 nucleotides from the beginning and from the end of the alignment were trimmed. After that, we excluded sequences (1) shorter than 29,000 bp, (2) with more than 3,000 (for Russian sequences) or 300 (for all other countries) positions of missing data (Ns), (3) excluded by Nextstrain [43], (4) in non-human animals, (5) with a genetic distance to the reference genome more than four standard deviations from the epi-week mean genetic distance to the reference, or (6) with incomplete collection dates. To this dataset, we added the 1,645 Russian sequences described in our earlier study [44] and 344 samples produced by the CoRGI consortium which had not been yet available in GISAID on April 15 (but have been deposited to GISAID since then). The final dataset consisting of 830,249 sequences, including 4,487 Russian samples, was then annotated by the PANGOLIN package (v2.3.8). For the categories in Fig. 1, we selected Pango lineages represented by at least 100 Russian samples (there were six such lineages: B.1, B.1.1, B.1.1.397, B.1.1.28, B.1.1.317 and B.1.1.294), added the two earliest lineages A and B and the VOC lineage B.1.1.7, and aggregated A, B, B.1 and B.1.1 with lineages nested in them except those included in other categories into A., B., B.1.* and B.1.1.*, respectively.
Data analysis. To trace the frequency dynamics of mutations, for each non-reference nucleotide at each position in each month, we calculated the fraction of samples with this nucleotide among all samples where this position contained an ambiguous nucleotide. We did this separately for the Russian and non-Russian samples, and selected changes with frequency more than 5% in S protein and more than 10% in other proteins in February-March 2021 (a total of 461 sequences) in Russian samples for consideration. Calculations were performed with custom Perl and R scripts. Wilson score intervals were estimated using Hmisc R package [45], and results were visualised with the ggplot2 package [46] of R language [47]. Upset plots were built with the UpSetR package [48] for R. Logistic growth models were fit to frequencies of each variant averaged across 14-days sliding windows with nls() function of R language [47]. Only windows with total number of samples > 20 were taken into account. Confidence intervals for estimated parameters were obtained with confint2 function from nlstools R package [49], similar to [41]. Results were visualised with R packages ggplot2 [46], tidyverse [50] and gridExtra [51].
Mapping residues onto the S-protein structure. To visualize spike mutations, we utilized two different spike protein structures, corresponding to S-protein in complex bound with 4A8 (PDB ID: 7c2l) or with P5A-1B9 (PDB ID: 7czx) antibody. The NTD antibody binding epitope is defined as in [24]. The two structures were structurally aligned and visualized with Open-Source PyMOL52.
Acknowledgements
We are grateful to all GISAID submitting and originating labs for rapid open release of SARS-CoV-2 sequencing data. We thank Sergei L Kosakovsky Pond for help with HyPhy analyses, and Evgeniya Alekseeva and members of the Bazykin lab for fruitful discussions. This work was supported by the RFBR grant 20-54-80014 to G.A.B.
Supplementary Information
Fig. S1. Frequency dynamics of SARS-CoV-2 amino acid changes in different regions of Russia. Notations are the same as in Fig.1.
SupplFigure1.pdf (1.0 MB)