Our preprint, “Petabase-scale sequence alignment catalyses viral discovery” is now online.
We’ve aligned 3.84 million libraries to all reference vertebrate viruses (except retroviruses) and created an explorable website (https://serratus.io) of the data.
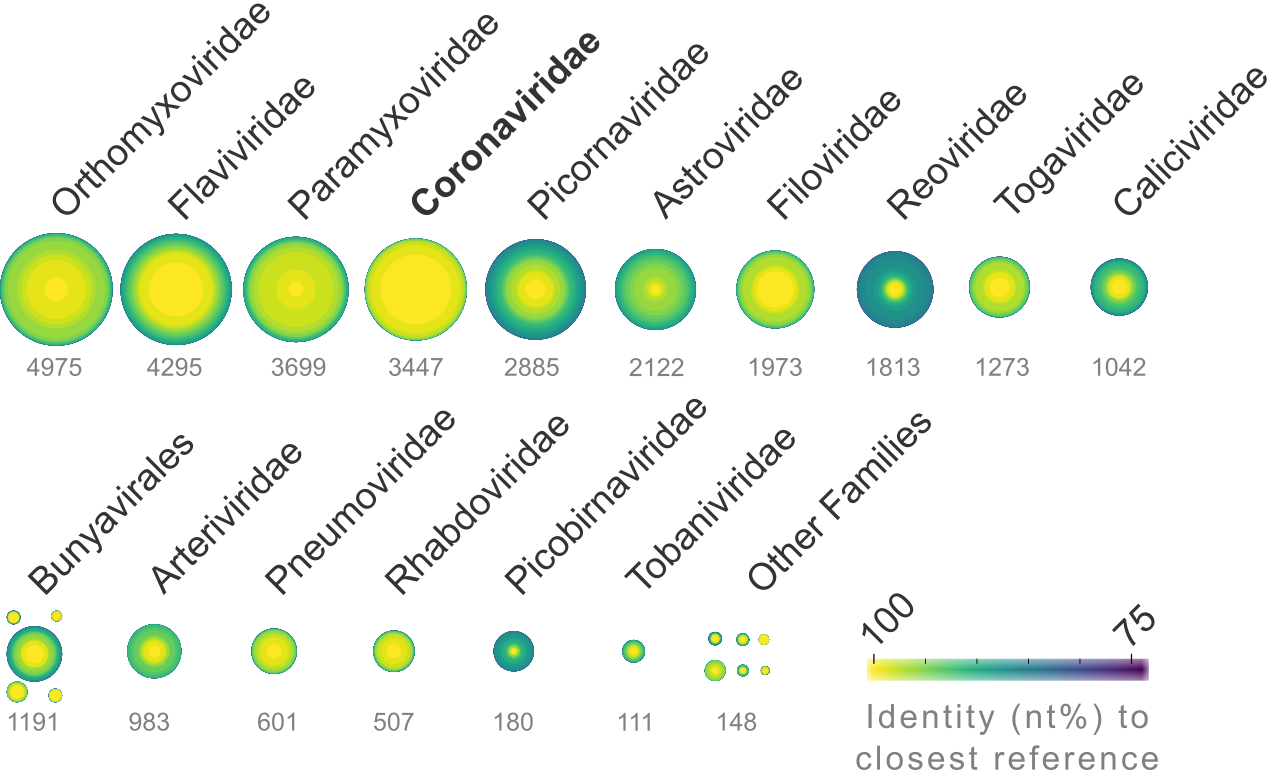
The site is under active development and we’re especially looking for feedback to improve the web interface. How can we make this data more ‘explorable’ and help you find the virus/datasets you’re looking for? For programmatic access the R/postgreSQL package, “Tantalus” is the current best option.
Once again all our data is public/cc0 so if you think any of this work can help your ongoing CoV research and you can’t find the data you’d like on your own, don’t be shy to reach out.